
Using Albert Bandura’s theory of self-efficacy (1977) as a theoretical base, we designed the Institute for Research Design in Librarianship (IRDL) to address the four main sources of influence on self-efficacy: mastery experiences, social persuasion, modeling, and emotional arousal. We interpreted the component of “mastery experiences” as successfully learning new tasks, providing the participants with the ability to persevere in the face of obstacles. We interpreted “social persuasion” to structured situations in which the participants receive encouragement and experience success in working through challenges. We viewed “emotional arousal” as how people were feeling when they were in the research process. We interpreted “modeling” to allow for viewing the research process of the other Scholars in their cohort, as well as having access to a formal mentor to provide accurate guidance on the research process. Over the course of IRDL we designed multiple points of measurement to assess the efficacy of those components.
To assist us in developing sound assessment mechanisms, in the first year of IRDL (2014) the two program co-investigators (me and Kristine Brancolini) collaborated with two staff members on campus who focused on assessment metrics as part of their regular work. Leading the IRDL assessment effort was the LMU Director of Assessment, Laura Massa, and the LMU Manager of Surveys and Evaluation, Christine Chavez. The four of us mapped the desired outcomes of the program and designed appropriate assessment tools to measure how successful the program model was in meeting the outcomes.
Since we based the design on the components of the Bandura theory, our initial focus of assessment was on them. To determine the possible gains program participants had related to mastery experiences, we used a confidence scale we designed around the components of the research process. To measure possible changes related to social persuasion, we used a personal network series of surveys over the course of the year, to observe the nature of the research-related relationships the participants developed. To determine how the Scholars were self-regulating, we checked in with them via a survey, at the mid-point in the year-long experience. To determine how a mentor-mentee relationship may have affected the participants sense of confidence, we created a survey for the mentors and a separate survey for the participants (the mentees), that was delivered at the end of the program.
With each year of the IRDL program, we had nine separate formalized assessments in place, to help us evaluate if we were meeting our programmatic goals: 1) the confidence scale noted above; 2) a series of research network surveys, noted above; 3) a post-workshop survey; 4) an external review; 5) a pre-/post-workshop research proposal evaluation; 6) a mid-point check-in survey; 7) a summative survey; 8) a mentor feedback survey, noted above; and 9) a scholar feedback survey on the mentor program, noted above.
In a series of blog posts I will focus on each assessment, when it was delivered, what mechanism of data collection was used and its analysis, how much the assessment cost, and a reflection on its effectiveness in measuring what we intended.
I include here the annual schedule, showing the year according to the grant terms, that I used to coordinate the assessments.
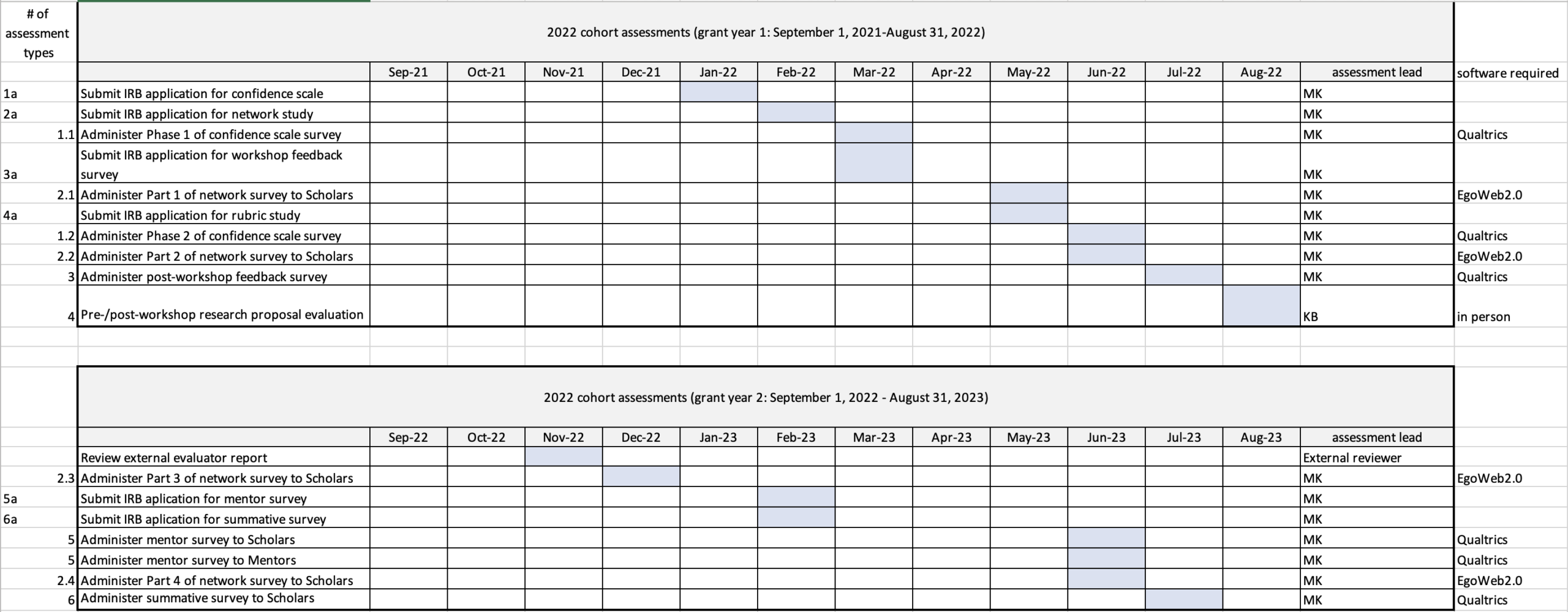
I want to put “ask me about my Gantt chart” on a t-shirt someday.

Pingback: Confidence scale (Assessments of the IRDL program) | Organization Monkey
Pingback: Research networks of the IRDL participants (Assessments of the IRDL program) | Organization Monkey